
Kernel bypass is a technique that allows applications to communicate directly with hardware - like network interface cards (NICs) - bypassing the Linux kernel's networking stack. This reduces latency and improves performance, which is critical in high-frequency trading (HFT), where every microsecond matters.
Key takeaways:
- Why it matters: Traditional Linux networking introduces delays that are too slow for HFT, especially at speeds of 100 GbE and above.
- Technologies: DPDK, RDMA, and AF_XDP are leading kernel bypass solutions, each offering unique methods to minimize latency.
- Hardware requirements: High-performance NICs, FPGAs, and RDMA-capable setups are essential. NVIDIA's ConnectX-6 adapters and FPGA solutions are examples of tools used to achieve sub-microsecond latencies.
- System tuning: Techniques like CPU isolation, disabling power-saving features, and optimizing NUMA configurations are critical to achieving low latency.
For HFT systems, kernel bypass technologies like DPDK and RDMA are indispensable for processing market data and sending orders at lightning speeds. With proper hardware and system configurations, firms can achieve latencies as low as single-digit microseconds, staying competitive in a field where every microsecond counts.
Linux System Requirements for Kernel Bypass
Hardware Requirements for Ultra-Low Latency
Achieving success with kernel bypass techniques like DPDK, RDMA, and AF_XDP hinges on using top-tier hardware and fine-tuning Linux configurations. These methods demand hardware specifically tailored for ultra-low latency performance.
For starters, high-performance Network Interface Cards (NICs) are essential. These NICs enable direct data transfers between user-space memory and the NIC itself, cutting out unnecessary overhead. Modern NICs can achieve speeds exceeding 200 GbE, with some advanced models reaching up to 1.6 Tbps.
A notable example comes from NVIDIA, which showcased how its ConnectX-6 adapters, paired with Rivermax technology, deliver data directly to applications at 25 GbE, significantly reducing latency. Similarly, FPGA-based systems are designed to handle trading logic in hardware, minimizing delays. According to NVG Associates Inc., FPGA-based high-frequency trading (HFT) systems using the Solarflare Application Onload Engine consistently achieve latencies between 750–800 nanoseconds for market events to order messages, with future optimizations expected to bring this down to 704–710 nanoseconds.
For RDMA, specialized NICs and network setups are required. These allow direct memory access between machines, bypassing the kernel entirely. Advanced NICs with TOE (TCP Offload Engine) further enhance performance by processing packets and protocols directly in hardware. For AI-powered trading strategies, NVIDIA GPUs featuring GPUDirect technology enable NIC-to-GPU direct memory access, skipping the CPU altogether to speed up market data analysis.
However, hardware alone isn’t enough - proper system tuning is key to unlocking the full potential of ultra-low latency setups.
System Tuning for Low-Latency Performance
To complement high-performance hardware, precise Linux system tuning is essential. By default, the Linux kernel’s networking stack isn’t configured for latency-sensitive tasks, but targeted adjustments can significantly improve performance.
One effective strategy is CPU isolation, where specific CPUs are reserved exclusively for latency-critical workloads. This minimizes interruptions caused by other system processes and reduces jitter. Additionally, configuring NICs to use polling mode drivers instead of interrupt-driven handling helps reduce context-switching, speeding up packet processing. Together, these adjustments work alongside advanced hardware to ensure minimal processing delays.
How QuantVPS Supports HFT Infrastructure
Deploying kernel bypass techniques in real-world applications requires a dependable infrastructure. QuantVPS offers a high-performance platform designed for ultra-low latency, delivering connectivity as fast as 0–1 ms and guaranteeing 100% uptime [website].
The platform is built with powerful CPUs, NVMe storage, and robust network connections - offering 1 Gbps+ speeds on standard plans and up to 10 Gbps+ on dedicated servers [website]. With full root access, users can directly implement critical optimizations like CPU isolation, polling mode drivers, and kernel tweaks, ensuring their systems achieve the low-latency benchmarks required for kernel bypass [website].
QuantVPS also includes features like DDoS protection and automatic backups, creating a secure and resilient environment for trading. Whether you’re working with custom C++ systems that typically operate at 3–5 microseconds of latency or advancing to more advanced kernel bypass methods, QuantVPS provides the infrastructure needed to support your HFT goals.
Run 24/7 while you sleep. Keep bots, platforms, and trade copiers online on a dedicated VPS.
Low-latency VPS hosting for your trading platform.
From $59.99/mo
DPDK for ultra low latency applications - Muhammad Ahmad & Ali Rizvi, eMumba Inc.
Kernel Bypass Technologies for HFT
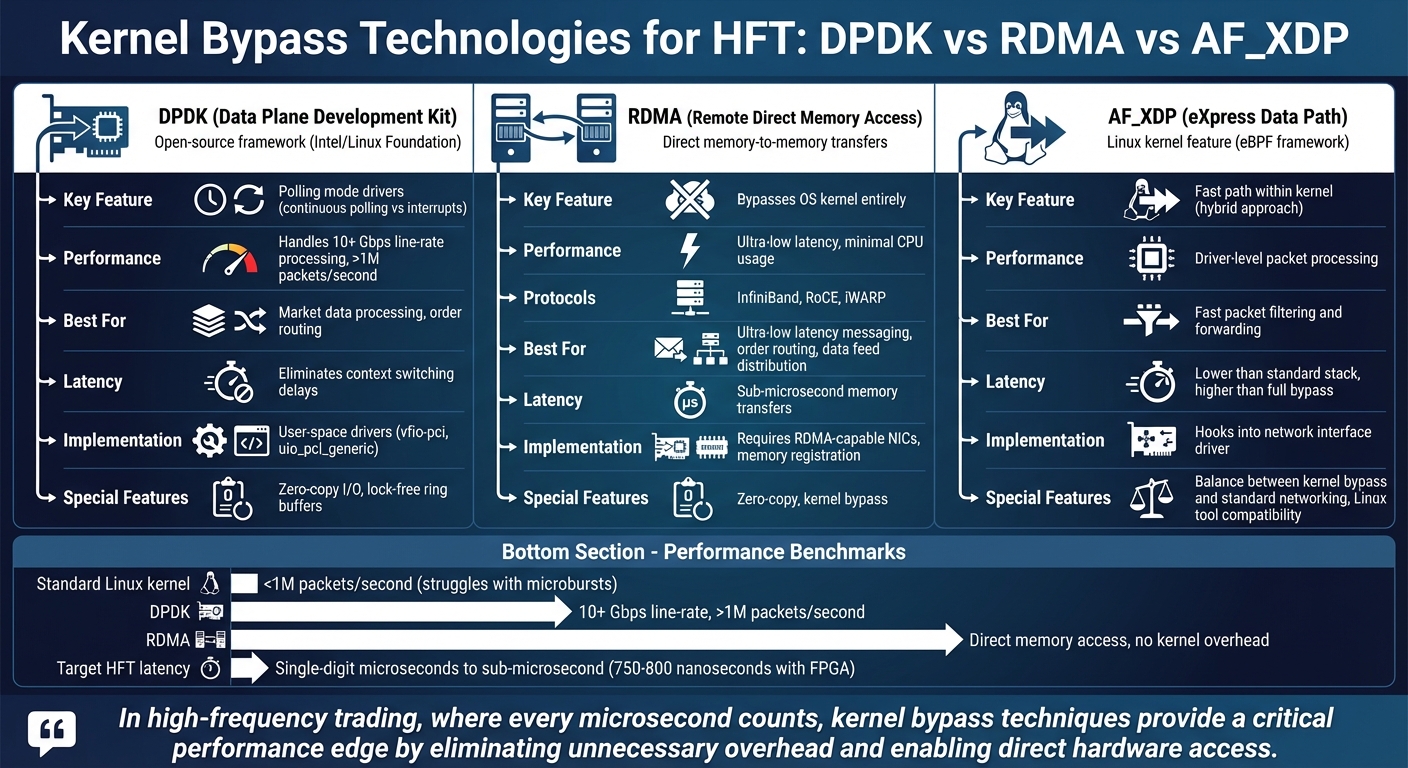
Kernel Bypass Technologies Comparison: DPDK vs RDMA vs AF_XDP for HFT
After optimizing hardware and system settings for low-latency performance, kernel bypass technologies offer specialized solutions tailored to the unique demands of high-frequency trading (HFT).
DPDK: Data Plane Development Kit
DPDK, an open-source framework originally developed by Intel and now overseen by the Linux Foundation, provides libraries and drivers that enable direct access to network interface cards (NICs).
The standout feature of DPDK is its polling mode drivers. Unlike traditional interrupt-driven methods, DPDK continuously polls the NIC for incoming packets, eliminating the delays caused by context switching. This approach dramatically boosts packet throughput. For example, while standard Linux kernel networking stacks struggle to handle traffic rates above 1 million packets per second - typical during microbursts in large exchanges - DPDK supports line-rate processing at 10 Gbps or higher, ensuring no packets are lost.
"In high-frequency trading, where every microsecond counts, kernel bypass techniques provide a critical performance edge by eliminating unnecessary overhead and enabling direct hardware access." - Yogesh
DPDK is particularly effective for market data processing and order routing, where handling high volumes of packets with minimal latency is crucial. By bypassing the kernel, it ensures packets move directly from the NIC to the application with minimal delay.
RDMA: Remote Direct Memory Access
RDMA allows direct memory-to-memory data transfers between servers without involving the operating system kernel, reducing both latency and CPU usage.
There are three main RDMA technologies: InfiniBand, RoCE (RDMA over Converged Ethernet), and iWARP. Each requires specific NICs and network configurations but provides ultra-low latency for specialized tasks in HFT.
In trading environments, RDMA is ideal for ultra-low latency messaging, order routing, and data feed distribution. It’s especially useful for internal communication between components like risk engines or for disseminating market data feeds across systems. By bypassing the standard networking protocols, RDMA minimizes overhead and maximizes efficiency.
AF XDP: Lightweight Kernel Bypass
AF_XDP (eXpress Data Path) is a Linux kernel feature within the extended Berkeley Packet Filter framework. Unlike DPDK and RDMA, which operate primarily in user-space, AF_XDP works within the kernel but offers a fast path for packet processing by hooking directly into the network interface driver.
This setup allows user-level programs to interact directly with the NIC while still retaining some kernel involvement. By processing packets at the driver level, AF_XDP avoids much of the traditional networking stack’s overhead, enabling fast packet filtering and forwarding.
AF_XDP strikes a balance between full kernel bypass and conventional networking. It’s a practical choice for Linux-based trading systems that require quick packet processing but don’t need the complete kernel bypass provided by alternatives like DPDK. This technology enhances performance for latency-sensitive applications while remaining compatible with standard Linux networking tools.
How to Implement Kernel Bypass on Linux
Building on the earlier discussion of hardware and technologies, let's dive into the steps to implement kernel bypass on Linux. This process involves precise configuration and system-level tweaks to meet the ultra-low latency demands often required in high-frequency trading (HFT). Technologies like DPDK, RDMA, and AF_XDP each have unique setup processes, and their configuration significantly influences performance.
Setting Up DPDK for HFT Applications
To get started with DPDK, you'll need to configure hugepages (either 2 MB or 1 GB) by editing /etc/sysctl.conf or using runtime commands. Hugepages help reduce memory management overhead, which is critical for latency-sensitive applications. After that, bind your NICs to DPDK-compatible user-space drivers, such as vfio-pci or uio_pci_generic, using the dpdk-devbind.py script. This step detaches the NIC from the kernel and hands over control to user-space drivers, enabling direct access to the NIC's buffers.
DPDK's polling mode drivers continuously monitor for incoming packets, removing the delays caused by context switching. Instead of relying on interrupts, your application directly processes packets from the NIC's ring buffers, speeding up the entire workflow.
Another key feature of DPDK is zero-copy I/O, which allows packets to move directly between the NIC and the application's buffers without intermediate copying. To maintain consistent throughput during high trading volumes, you can implement lock-free or wait-free ring buffers, ensuring producer and consumer threads operate without blocking each other.
Configuring RDMA for Low-Latency Messaging
For RDMA, start by installing RDMA-capable NICs that support InfiniBand, RoCE, or iWARP protocols. You'll also need to install the appropriate drivers and libraries, such as libibverbs and rdma-core. Memory registration is a crucial step - it pins physical memory pages and grants the NIC direct access rights, enabling data transfers that bypass the traditional TCP/IP stack.
Next, configure queue pairs, which act as communication endpoints between systems. These can be set up for reliable connections, such as order routing, or as unreliable datagrams for market data feeds where occasional packet loss is tolerable.
Once RDMA is configured, you'll need to fine-tune the system to ensure these optimizations deliver consistent, low-latency performance.
Linux Tuning for Kernel Bypass Efficiency
To maximize the effectiveness of kernel bypass, you need to optimize the Linux environment. This involves isolating CPU cores and disabling kernel features that introduce delays. Key adjustments include:
-
Isolating CPU cores: Use the
isolcpuskernel boot parameter to dedicate specific cores to trading applications, ensuring they aren't interrupted by other tasks. -
Disabling CPU frequency scaling: Set the CPU governor to
performancemode to prevent frequency fluctuations. - Turning off power management features: Disable C-states to avoid latency spikes caused by power-saving transitions.
-
Pinning processes to NUMA nodes: Use tools like
numactlto ensure memory accesses stay local to the NIC's NUMA node, minimizing latency and context switching.
These optimizations create a predictable execution environment, reducing interference from other system processes and improving overall performance.
Stay online and closer to execution. Choose a VPS location for CME futures, New York markets, London FX, API trading, and more.
Host your platform near the market route that matters.
From $59.99/mo
Building an HFT Infrastructure with Kernel Bypass
Designing a Low-Latency Linux Architecture
To build a high-frequency trading (HFT) system with minimal latency, it's essential to dedicate specific CPU cores to critical components like feed handlers, order gateways, and risk engines. This approach prevents resource contention and ensures smooth, interference-free operations.
Keep the data paths as short as possible. For instance, feed handlers that use DPDK or RDMA should be placed on the same NUMA node as the NIC handling market data. This setup reduces memory access delays by avoiding cross-NUMA communication. Similarly, ensure that order gateways are positioned on CPU cores near the NIC responsible for sending orders to the exchange.
For inter-process communication, shared memory is your best bet. Techniques like lock-free ring buffers allow components to exchange data efficiently without the overhead of network sockets, keeping latency in check.
Once the architecture is in place, measure your system’s latency in detail to identify areas for further optimization.
Measuring and Validating Latency
Tick-to-trade latency - measuring the time from when market data arrives to when an order is sent - is a critical benchmark for HFT systems. Use NIC hardware timestamping for precise measurements at each stage.
Tools like perf and RDTSC-based logging can help pinpoint bottlenecks. Log timestamps at key points: when the NIC receives a packet, when the application processes it, after the trading logic executes, and when the order is dispatched. This breakdown makes it easier to identify where delays occur.
To ensure reliability, run microbenchmarks under real-world conditions, such as during heavy market data bursts. Pay attention to any jitter or tail latency spikes, as these anomalies can significantly impact trading performance.
Using QuantVPS for Deployment
QuantVPS provides a strong foundation for ultra-low latency trading. Their VPS Ultra+ plan offers 24 dedicated cores and high-performance networking, while Dedicated+ Servers deliver 10Gbps+ connectivity, ideal for isolating DPDK or RDMA tasks.
The platform’s proximity to major exchange data centers reduces network propagation time, helping market data reach your server faster. With NVMe storage included in every plan, you can log high-frequency tick data without worrying about I/O slowdowns.
QuantVPS also handles essential infrastructure needs like DDoS protection, automatic backups, and system monitoring. This allows you to focus on fine-tuning your kernel bypass setup and optimizing your trading logic. With full root access, you can configure everything from CPU core isolation to hugepages, ensuring your HFT system runs at peak efficiency.
Conclusion
How Kernel Bypass Benefits HFT
Kernel bypass technologies are a game-changer for achieving ultra-low latency in high-frequency trading (HFT). By bypassing the Linux kernel entirely, network packets can move directly from the network interface to your application, cutting out kernel-related overhead like scheduling, memory management, and additional checks. This direct path not only speeds up packet processing but also gives you more control over the hardware, eliminating bottlenecks.
The perks don’t stop there. Offloading packet processing reduces CPU usage, while zero-copy architectures eliminate unnecessary data transfers between kernel and user space. Plus, deterministic execution with minimal jitter ensures the consistent timing that HFT algorithms demand. For ultra-low latency systems, every microsecond counts - modern trading systems aim for round-trip times under 10 microseconds, with some even targeting single-digit microseconds or nanoseconds for tick-to-trade operations.
Steps to Further Optimize Your Infrastructure
To take full advantage of kernel bypass, start by implementing tools like DPDK or RDMA for network I/O. Extend these principles to other system resources by using SPDK for direct NVMe SSD access or leveraging RDMA for inter-process communication. Fine-tune your setup with strategies like isolating CPU cores using isolcpus, disabling swap and transparent huge pages, and configuring interrupt affinity to ensure latency-critical cores remain interference-free.
For a solid foundation, QuantVPS offers tailored infrastructure solutions. Whether it’s the VPS Ultra+ with 24 dedicated cores or Dedicated+ Servers with 10Gbps+ connectivity, their proximity to major exchange data centers ensures you’re always close to the action. Features like NVMe storage across all plans, full root access for custom kernel bypass configurations, and built-in DDoS protection allow you to focus on refining your trading logic. Combining specialized hardware, precise system tuning, and kernel bypass technologies, you’ll be well-positioned to achieve the sub-10 microsecond latencies essential for staying competitive in HFT.
FAQs
What are the main differences between DPDK, RDMA, and AF_XDP for reducing latency in HFT?
DPDK, or Data Plane Development Kit, is designed to cut down on latency by bypassing the kernel entirely. Instead, it directly accesses NICs (Network Interface Cards) using polling mode drivers. This approach eliminates the delays associated with traditional interrupt-driven processing, making it a go-to solution for high-speed networking needs.
RDMA, short for Remote Direct Memory Access, takes a different approach. It allows machines to transfer data directly between their memory systems without involving the CPU or even the TCP/IP stack. The result? Blazing-fast communication speeds that are ideal for scenarios requiring ultra-low latency.
Then there’s AF_XDP, a component of the eXpress Data Path (XDP) framework. Operating at the driver level, it focuses on filtering and forwarding packets as early as possible in the network stack. This early intervention ensures minimal latency, making it a strong choice for high-performance applications.
While each of these techniques is tailored to specific scenarios, they all share a common goal: reducing network latency and boosting performance. This makes them indispensable tools for high-frequency trading professionals working on Linux systems.
How does choosing the right hardware reduce latency in high-frequency trading systems?
Choosing the right hardware plays a key role in cutting down latency in high-frequency trading (HFT) systems. High-performance network interface cards (NICs), such as Mellanox ConnectX, paired with specialized technologies like RDMA (Remote Direct Memory Access), can drastically speed up data transfers and reduce the load on CPUs. These improvements enable faster packet processing, which is essential for achieving ultra-low latency.
Investing in hardware tailored for high-speed networking and low-latency tasks allows HFT professionals to boost the efficiency and performance of their trading systems, keeping them competitive in the lightning-fast world of trading.
What are the key steps to optimize a Linux system for ultra-low latency in high-frequency trading?
To achieve ultra-low latency on Linux for high-frequency trading (HFT), focus on these critical optimizations:
- Use kernel bypass techniques such as DPDK, RDMA, or XDP to cut down on overhead and boost network performance.
- Pin workloads to specific CPUs to limit context switching and maximize processing efficiency.
- Disable hyper-threading to allocate dedicated CPU resources for essential tasks.
- Enable CPU isolation to keep non-essential processes from interfering with critical operations.
- Fine-tune network interface cards (NICs) by adjusting settings like interrupt coalescing and ring buffer sizes.
-
Adjust key system parameters, such as
SO_BUSY_POLL, and configure interrupt affinity to align interrupts with the most suitable CPU cores.
These optimizations are designed specifically for HFT professionals aiming to speed up data processing and cut trading latency on Linux systems.







