
AI has transformed futures trading by enhancing market analysis, trade execution, and risk management. Platforms like Trade Ideas, Tickeron, Alpaca, Cryptohopper, and QuantVPS stand out by offering unique AI-driven tools. Here's what you need to know:
- Trade Ideas: Features HOLLY AI for real-time insights and integrates with major brokers like Interactive Brokers and E*TRADE. Pricing starts at $118/month.
- Tickeron: Offers pattern recognition and trade predictions. Plans start at $250/month with a free trial available.
- Alpaca: Developer-focused with commission-free trading and robust APIs for algorithmic strategies.
- Cryptohopper: Automates crypto futures trading with adaptive bots. Plans range from $24.16 to $107.50/month.
- QuantVPS: Provides ultra-low latency VPS solutions for high-frequency trading, starting at $59/month.
Quick Comparison:
| Platform | Monthly Cost | Key Features | Focus Area |
|---|---|---|---|
| Trade Ideas | $118+ | HOLLY AI, brokerage integrations | Stocks |
| Tickeron | $250+ | Pattern recognition, trade predictions | Multi-asset |
| Alpaca | Free–$200 | APIs for algo trading | Stocks & Crypto |
| Cryptohopper | $24.16–$107.50 | Adaptive bots for crypto trading | Crypto |
| QuantVPS | $59–$299 | Low-latency VPS for high-frequency trading | Infrastructure |
AI is reshaping futures trading, but choosing the right platform depends on your trading focus, technical expertise, and budget. Read on for a detailed breakdown of each platform.
Best A.I. for Futures Trading? | A Real-Life Success Story
1. Trade Ideas
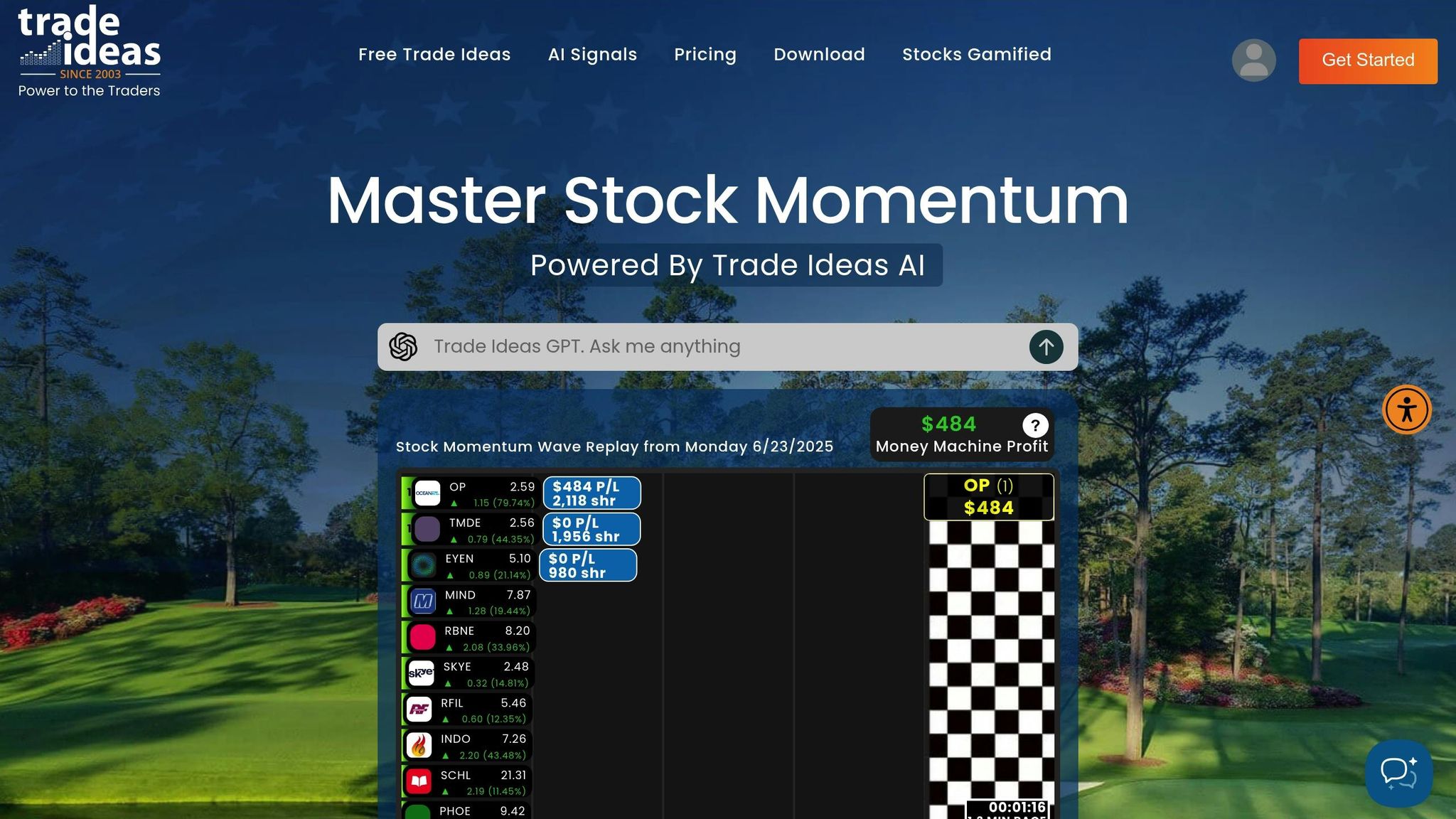
Trade Ideas is an AI-driven platform designed to provide traders with advanced market analysis and actionable insights. At the heart of the platform is its flagship AI system, HOLLY, which operates nonstop, analyzing massive datasets. This includes monitoring market activity, news, and even social media sentiment across all U.S. equities. HOLLY employs roughly 40 distinct trading strategies to help traders stay ahead of the curve.
AI Capabilities
HOLLY's strength lies in its ability to simulate millions of trades overnight. Each trading day, it generates 5–7 scenarios with the potential to outperform the market. Another standout feature is Money Machine, a second-generation AI built for real-time momentum trading. This tool identifies and positions traders in the top three performing stocks of the day automatically. Additionally, TradeWave's AI continuously evaluates market data, adjusting exponential moving average (EMA) bands in real time to provide clear buy and sell signals.
The platform also incorporates built-in risk management tools, issuing immediate alerts when pre-set trading limits are breached during market hours.
Integration with Trading Platforms
Trade Ideas is designed to work seamlessly with major brokerage platforms, making trade execution smooth and efficient. For example, its Brokerage Plus service integrates directly with Interactive Brokers (IBKR), enabling users to manage portfolios and execute trades at low costs right from the Trade Ideas interface.
It also connects with E*TRADE through the same Brokerage Plus integration. For traders using CenterPoint Securities, access to Trade Ideas is included at no additional cost through the CenterPoint Edge program. Meanwhile, Cobra Trading users gain access to advanced trading tools and direct order routing powered by Trade Ideas technology.
This wide-ranging compatibility highlights the platform's focus on providing a seamless trading experience.
Pricing
Trade Ideas offers various pricing tiers to suit different needs. The free plan includes delayed data, while the Standard plan costs $118 per month ($999 annually). The Premium plan is priced at $228 per month ($1,999 annually). Additional options include the Birdie Bundle at $89 per month ($1,068 annually) and the Eagle Elite at $178 per month ($2,136 annually). Add-ons are also available for those seeking specialized tools.
2. Tickeron
Tickeron is an AI-driven platform designed to support futures traders - whether they're just starting out or seasoned experts - by combining artificial intelligence with human insights to evaluate the market effectively.
Run 24/7 while you sleep. Keep bots, platforms, and trade copiers online on a dedicated VPS.
Low-latency VPS hosting for your trading platform.
From $59.99/mo
AI Capabilities
Tickeron offers a suite of AI tools aimed at improving trading decisions. Its Trend Prediction Engine analyzes historical data to predict price movements, while the Pattern Search Engine scans assets like stocks and ETFs for technical patterns such as triangles, flags, and wedges. These tools provide detailed insights, including profit probabilities, trade triggers, and alerts, alongside a Confidence Level for each trade idea.
Integration with Trading Platforms
Tickeron integrates its AI Robots directly with brokerage accounts, enabling live trades. Additionally, the company is working on a fourth-generation feature to connect Virtual Accounts for fully automated trading. This development simplifies the trading process and allows users to evaluate different platforms' pricing and services seamlessly.
"Tickeron's Virtual Accounts mark a significant milestone in the company's history and reinforce its position as a leader in AI-powered trading tools. The groundbreaking risk management tools are game-changers for traders looking to navigate the complexities of the financial markets. They enable us to effectively help our users simplify their trading activity by copying trades from our VAs." – Sergey Savastiouk, Ph.D., CEO and Founder of Tickeron.
Pricing
Tickeron offers a free plan for beginners, alongside premium options. The "Expert" plan is priced at $250 per month, with an annual subscription reducing the cost to $125 per month. A 14-day free trial is also available for users to explore the platform.
3. Alpaca
For futures traders exploring algorithmic strategies, Alpaca offers a developer-focused platform that, while centered on equities, options, and crypto, provides valuable insights applicable to futures trading strategies.
AI Capabilities
Alpaca's APIs power AI-driven algorithms designed to analyze market data and news in real time, identifying patterns and trends. These algorithms are built to learn and evolve, fine-tuning trading strategies based on market performance.
The API supports advanced features such as margin trading and short selling, enabling the creation of complex algorithmic strategies. This adaptability allows traders to automate responses to shifting market conditions. Notably, a 2020 JPMorgan study found that over 60% of trades exceeding $10 million were executed using algorithms. These AI tools make Alpaca a flexible option for integrating advanced trading systems.
Integration with Trading Platforms
Alpaca provides API integration to develop trading algorithms and applications, as demonstrated by platforms like Zad App and Woodstock.
"Alpaca's Broker API has everything needed to build a full-fledged trading application out of the box. Building our backend infrastructure on top of Broker API was easier than expected, given their extensive documentation, ready-to-test sandbox environment, and professional support." – Abdulrahman Al Kharafi, CEO of Zad App & Head of Fintech Securities House
Performance and Infrastructure
Alpaca supports trading across more than 30 countries, offering access to equities, options, and cryptocurrencies. It caters to developers with SDKs available in multiple programming languages, including Python, .NET/C#, Go, and Node. Additionally, Alpaca features a testing environment where traders can simulate strategies before committing real funds. This paper trading setup is particularly useful for refining AI algorithms and minimizing risks during the transition to live trading.
Pricing
Alpaca operates on a commission-free model, with revenue generated through margin interest (7.5%), ACH return fees ($25), domestic wire fees ($25), and ADR pass-through fees ($0.01-$0.03 per share). While Alpaca itself remains fee-free for trades, third-party platforms using its API may charge additional fees. This pricing structure underscores Alpaca's goal of offering developer-friendly tools for algorithmic trading.
4. Cryptohopper
Cryptohopper is an AI-driven platform designed to automate futures trading. With 478,945 cryptocurrency traders already on board and more than 750,000 accounts created, it has carved out a solid position in the market.
AI Capabilities
At the heart of Cryptohopper is its Algorithmic Intelligence (AI) platform, which powers trading by analyzing strategies and tailoring approaches to match market conditions. The AI processes market data, identifies trends, and executes trades automatically, minimizing the need for constant manual oversight. It also supports grid trading bots for futures contracts, automating buying and selling based on preset rules. The system's adaptive intelligence continuously monitors market trends, fine-tuning strategies for each trading pair.
Greg Valladolid from synapseDeFi, Inc. praised Cryptohopper's capabilities, saying the platform has enabled his team to "visualize, deploy and automate various trading strategies to applicable markets. This has lead to an exponential increase...".
Integration with Trading Platforms
One of Cryptohopper's key strengths is its compatibility with over 18 exchanges, allowing traders to manage their portfolios in one place. The platform provides real-time updates on positions, charts, and order books, ensuring users stay informed about their automated strategies. For futures traders, this means trades can be executed seamlessly across multiple markets without the need to monitor each exchange individually. Its infrastructure is designed to handle both rising and falling markets, making it versatile for various trading conditions. With tens of billions in trading volume generated, the platform demonstrates its scale and reliability.
Performance and Infrastructure
Cryptohopper equips traders with tools to fine-tune their strategies, including backtesting capabilities that use historical data to evaluate performance. Its cloud-based system supports a "set and forget" style of trading, ideal for those who want to stay active in the market without constant monitoring. Strategy interval checks range from 2 to 10 minutes, allowing for quick adjustments to market changes. The platform also offers a variety of technical indicators and event-based triggers, with premium plans supporting up to 75 bots and 10 event triggers. This range of tools ensures traders of all levels can find features tailored to their needs.
Pricing
Cryptohopper uses a tiered subscription model to cater to different trading styles and experience levels:
| Plan | Monthly Cost | Key Features | Open Positions | Strategy Interval |
|---|---|---|---|---|
| Pioneer | Free | Copy Bots, Portfolio Management | 20 per exchange | Manual trading only |
| Explorer | $24.16/month | Backtesting, Strategy Designer, Paper Trading | 80 per exchange | 10 minutes |
| Adventurer | $57.50/month | Advanced Features, More Bots | 200 per exchange | 5 minutes |
| Hero | $107.50/month | AI Strategies, Market Making, Arbitrage | 500 per exchange | 2 minutes |
The platform accepts a variety of payment methods, including PayPal, Visa, Mastercard, American Express, Apple Pay, Google Pay, Discover, and BitPay. New users can explore the Explorer package with a free 3-day trial before subscribing. Annual plans offer discounts, with the Hero plan saving $258 annually compared to monthly payments. This pricing structure ensures options for everyone, from beginners looking for basic automation to experienced traders seeking advanced AI-powered tools.
5. QuantVPS
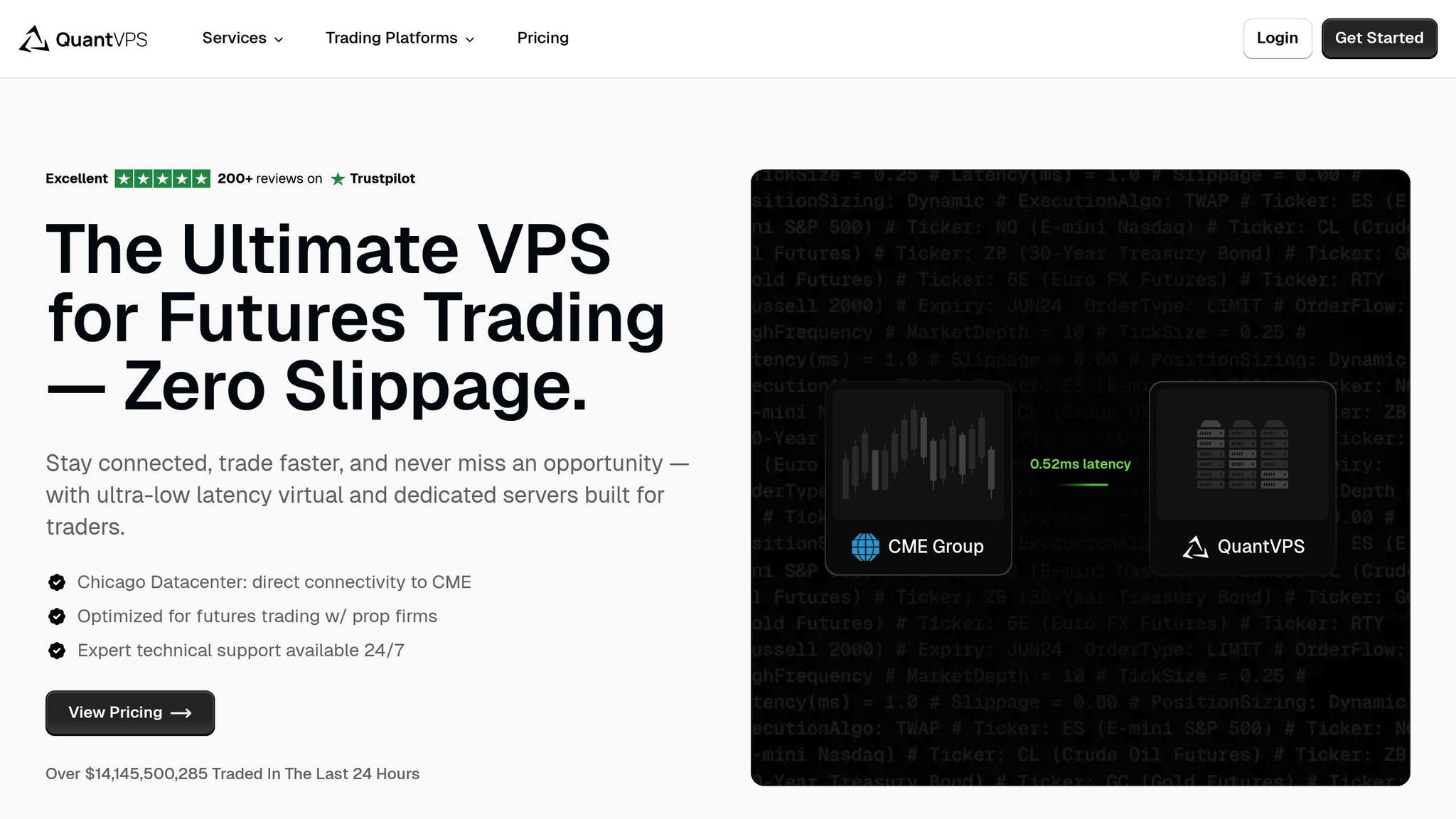
QuantVPS leverages advancements in AI to optimize infrastructure for sophisticated algorithmic trading strategies. With 92% of professional traders using specialized VPS solutions and algorithmic trading now accounting for nearly 80% of daily market activity, QuantVPS has positioned itself as a key player in supporting AI-driven trading operations. Its focus on reliable infrastructure and seamless integration with major trading platforms makes it an essential tool for serious futures traders.
Stay online and closer to execution. Choose a VPS location for CME futures, New York markets, London FX, API trading, and more.
Host your platform near the market route that matters.
From $59.99/mo
AI Capabilities
QuantVPS employs AI to dynamically allocate system resources like CPU and RAM based on the specific needs of each trading algorithm. Whether you're running complex neural networks or high-frequency trading strategies, this ensures optimal performance. The platform also supports automated trading bots and algorithmic strategies, with plans to expand its AI features to enhance strategy optimization and risk management.
Integration with Trading Platforms
QuantVPS integrates smoothly with leading futures trading platforms such as NinjaTrader, TradeStation, Quantower, Tradovate, and Interactive Brokers. It also supports popular futures data feeds like Rithmic, CQG, dxFeed, TT, and IQFeed [24]. For added convenience, traders can manage their strategies remotely through a secure desktop gateway [24]. The platform has earned strong user feedback, boasting a 4.8 rating on Trustpilot from 233 reviews [24].
Performance and Infrastructure
QuantVPS delivers ultra-low latency, with 0–1ms connectivity to CME servers. Its infrastructure is built on AMD EPYC processors, DDR4 RAM, and direct network connections to the CME in Chicago, ensuring maximum uptime and reliability. This setup allows AI algorithms to process market data and execute trades with unparalleled speed and precision.
"QuantVPS stands apart by being laser-focused on the needs of futures traders, especially those active in CME markets... Combine that with a support team that understands the nuances of CME trading workflows, and you've got a partner, not just a provider."
– Ryan, Co-founder and CEO of QuantVPS
Pricing
QuantVPS offers several pricing tiers to suit different trading needs and levels of complexity:
| Plan | Monthly Cost | Processor | RAM | Storage | Trading Complexity |
|---|---|---|---|---|---|
| VPS Lite | $59 | 4x AMD EPYC cores | 8GB DDR4 | 70GB NVMe | 1–2 charts, basic AI strategies |
| VPS Pro | $99 | 6x AMD EPYC cores | 16GB DDR4 | 150GB NVMe | 3–5 charts, moderate AI complexity |
| VPS Ultra | $199 | 24x AMD EPYC cores | 64GB DDR4 | 500GB NVMe | 5–7 charts, advanced AI algorithms |
| Dedicated Server | $299 | 16x+ cores | 128GB RAM | 2TB+ NVMe | 7+ charts, enterprise AI strategies |
All plans include 1Gbps+ network connectivity, unmetered bandwidth, and Windows Server 2022. For traders with specific needs, QuantVPS also offers specialized CrossTrade plans starting at $35/month, with a 30% discount available.
Advantages and Disadvantages
AI trading platforms bring a mix of strengths and challenges, catering to a range of trading preferences and expertise levels.
Trade Ideas stands out with its Holly AI, which boasts about 25% annual returns on stock picks. It analyzes extensive market data in real time, eliminating emotional bias in decision-making. However, its focus on U.S. and Canadian markets and the platform's complexity can be hurdles for beginners.
Tickeron offers detailed pattern recognition with verified performance metrics, providing audited results instead of theoretical backtests. It supports multiple asset classes, but the sheer number of features may overwhelm users, and its higher-tier plans can be costly for individual traders.
Alpaca attracts algorithmic traders with commission-free trading and a robust API for building custom strategies. It also offers a paper trading environment for risk-free testing. That said, using Alpaca effectively demands technical know-how, and its customer support may not match the comprehensiveness of traditional brokers.
Cryptohopper focuses on cryptocurrency trading, offering a marketplace for pre-built strategies and extensive customization options. Its 24/7 operation aligns perfectly with the nonstop nature of crypto markets. However, a steep learning curve and its exclusive focus on crypto make it less appealing for traders in traditional markets.
QuantVPS provides ultra-low latency infrastructure, with 0–1ms connectivity to CME servers - ideal for high-frequency trading. Its AI-driven resource allocation enhances system performance, earning a 4.8 Trustpilot rating from 233 reviews. The downside? It’s an infrastructure solution only, requiring separate trading software and data feeds.
| Platform | Monthly Cost | Key Strengths | Main Limitations |
|---|---|---|---|
| Trade Ideas | $90+ | Rapid pattern recognition, 25% annual Holly AI returns, real-time analysis | U.S./Canada focus, can be complex for beginners |
| Tickeron | $90+ | Audited performance metrics, robust pattern recognition | Feature overload, expensive higher tiers |
| Alpaca | Free–$200 | Commission-free trading, strong API integration | Requires technical expertise |
| Cryptohopper | $24–$108 | 24/7 operation, strategy marketplace | Limited to crypto markets, steep learning curve |
| QuantVPS | $59–$299 | Ultra-low latency (0–1ms), AI resource optimization | Infrastructure-only solution |
While AI platforms offer impressive tools to enhance trading efficiency, they also come with trade-offs in terms of focus, complexity, or scope, depending on the platform.
Beyond individual platform features, AI in futures trading provides notable advantages but also carries risks. These systems excel at continuous data analysis and risk management, processing massive datasets to predict risks and seizing market opportunities around the clock.
However, reliance on historical data can be a major drawback when market conditions shift beyond what an algorithm has been trained for. AI’s opaque decision-making can leave traders in the dark during unexpected events, and it lacks the intuitive judgment human traders bring to unprecedented situations. Security is another concern, as AI systems can be vulnerable to hacking and data breaches. Additionally, standardized strategies may not align with every trader’s risk tolerance.
To address these challenges, human oversight remains essential. Regular monitoring, thorough testing - such as paper trading - and backup systems can help minimize errors. Strengthening security with encryption and multi-layered protections is also critical to safeguard against cyber threats.
Conclusion
The world of futures trading is undergoing a dramatic transformation, with AI predicted to manage nearly 89% of global trading volume by 2025 and the AI trading market projected to hit $35 billion by 2030. This evolution isn’t just about smarter algorithms - it’s about combining cutting-edge AI with reliable, high-performance infrastructure.
Platforms like Trade Ideas, Tickeron, and Alpaca highlight how AI excels in analyzing vast datasets and managing risks, offering traders the ability to uncover opportunities with unmatched efficiency. AI systems can recalibrate valuations and risk metrics up to 100 times faster, but without ultra-low latency - such as QuantVPS’s 0–1ms CME connectivity - this speed advantage can be undermined.
Laurence Fink, CEO of BlackRock, aptly summarized this trend:
"AI, Aggregating All The Information"
By 2023, 99% of financial services firms had incorporated AI into their operations. However, simply using AI is no longer enough to gain an edge. The real advantage lies in pairing the right AI tools - whether for real-time analysis, automated execution, or risk management - with hosting solutions that offer seamless speed and reliability.
Success in futures trading now relies on mastering this balance. Traders must integrate AI’s analytical capabilities with infrastructure that ensures consistent, high-speed performance. This combination is essential for staying competitive and achieving long-term results in an increasingly AI-driven market.
FAQs
How can AI-powered platforms improve futures trading strategies?
AI-powered platforms are transforming futures trading by delivering real-time market insights, predictive analytics, and advanced risk management tools. These technologies enable traders to pinpoint the best entry and exit points, predict price movements using historical data, and handle leverage and margin with greater precision.
By automating intricate analyses and offering actionable insights, AI-driven tools streamline decision-making, enhance trading efficiency, and help traders stay ahead in the fast-moving world of futures trading.
What should I consider when choosing an AI platform for futures trading based on my skills and budget?
When choosing an AI platform for futures trading, you need to weigh your technical know-how and budget. Advanced platforms often provide more customization options and sophisticated tools, but they typically demand a solid technical background and come with steeper price tags. On the flip side, platforms with simpler, more user-friendly interfaces are ideal for those with limited technical skills. However, these may have higher subscription costs or offer fewer customization options.
Speaking of costs, the range can be quite broad. Building a custom AI solution can set you back anywhere from $30,000 to over $300,000, while pre-built platforms usually charge monthly fees between $89 and $228. Take a close look at your technical expertise, the features you need, and your budget to pick a platform that fits your trading goals and requirements.
How does AI improve trading platforms for faster and more efficient futures trading?
AI brings a new level of efficiency to trading platforms by enabling real-time market analysis and automated trade execution. These systems can process enormous amounts of data in just milliseconds, cutting down delays and reducing the chances of slippage during trades.
Another game-changer is the ability of AI-powered platforms to run around the clock. They constantly monitor markets and adapt strategies as conditions shift. This capability supports high-frequency trading, where thousands of trades are executed every second - giving traders an edge in fast-moving markets. On top of that, AI removes the influence of emotions from trading decisions, leading to more consistent and data-driven outcomes.







